I wanted to start off my blog with something simple to dip my feet in the water, and so I’m going to go with Bayes’ Theorem. Here it is:

This guy is single-handedly responsible for creating an entire branch of statistics, and it so simple that its derivation is typically done in an introductory class on the topic (usually in the first couple weeks when you’re going over the basics of probability theory). It’s not until you go into more advanced classes that one realize it has a lot more to say than how big the ratio is of the cross section of circles on a Venn diagram. When I was taught Bayes’ Theorem I just thought of it as a nifty little trick for converting 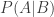
Fast forward 2 years later and I actually DO see it bullshit again. And surprise, it’s used for EVERYTHING. In fact, there is an entire field of mathematics dedicated to understanding its properties. It provides a new way of not just looking at statistics, or of probability, but of human knowledge! Bayes’ Theorem tells us to stop looking as our knowledge as some fixed property. The world may contain true and false statements about itself, but our knowledge about it is constantly fluctuating with new evidence, and we need to update our ideas about the world accordingly based on that evidence.
So let’s look back at the original theorem. I don’t like the way it’s usually written. Instead I’d like to make a small adjustment.

My little improvement on Bayes’ Theorem consists of just highlighting the little adjustment factor given by 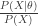

So let’s think of 

So how can you tell if someone is actually working for the Illuminati? Well, every once in a while they’ll throw out a hand signal (sort of like a low key gang sign). See exhibit A:

So one day Jeff Bezos is giving a keynote address and he decides to sit down. Lo and behold the camera gives him a quick glance and this creep is throwing out this ungodly hand sign, signaling his complicity in a hostile world-takeover by our Satanic overlords. Or he could’ve just randomly rested his hands there for no particular reason (like I said, I’m open minded). Let’s assign a value to these two possible explanations….
Let’s call the act of giving the hand signal our evidence 



Well, I definitely think he’s more likely to bring about the New World Order than I did before, but not by a significant enough margin to spout apocalyptic nonsense via HAM radio…
I could go on and on about this wonderful little equation. I can talk endlessly about how it is the most powerful epistemological statement in modern philosophy. But the fact is: you already use it in your every day life. Perhaps not as precisely as you should, but you are using it loosely every time your beliefs change. Every time you are presented some piece of evidence about the world and what is happening with it. Every time you’re not sure if Bitcoin is a good value after the last dip, or when you’re absolutely confident that all pickles taste like ass after your hundredth try. Next time you’re reading a news article think about how your beliefs are being updated, and to what degree and why.
Now I’d like to ask the reader: When was the last time you changed your mind about something? Can you assign numbers to your beliefs? If you would like to go beyond what I discussed, try asking yourself how robust your inferences are. How much do your posterior beliefs change based on your prior assumptions? Change up your values and come up with a basic “sensitivity” analysis.
Let me see what you come up with!
-Mason
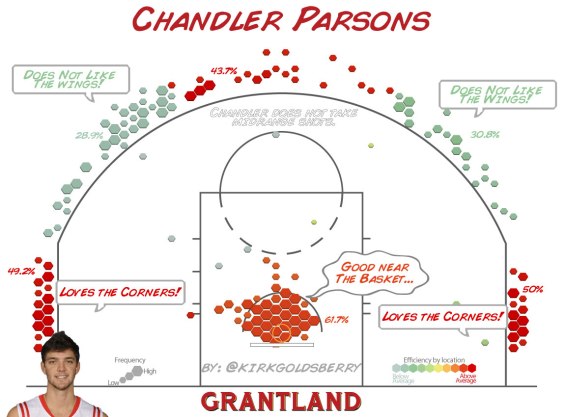
 represent the number of players in the league, and let each player in the league be indexed by
represent the number of players in the league, and let each player in the league be indexed by  , where
, where 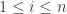 . Furthermore, let the expected point value of player
. Furthermore, let the expected point value of player  on the court be represented by
on the court be represented by 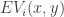 . Then we’ll define the player’s total offensive value as
. Then we’ll define the player’s total offensive value as
 represents the two dimensional court space, and
represents the two dimensional court space, and 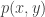 represents the probability at which player can get to position
represents the probability at which player can get to position  represents the value of player
represents the value of player 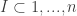 be a 5-tuple, where each element is different. This will represent 5 different players in the league. Then the value any 5-team offense at any position on the court can be represented by
be a 5-tuple, where each element is different. This will represent 5 different players in the league. Then the value any 5-team offense at any position on the court can be represented by  . That is, the value of the team at position
. That is, the value of the team at position 
 in a manner that is both calculable and useful.
in a manner that is both calculable and useful.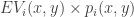 using standard
using standard