During my graduate degree program in Statistics I needed to know the ins and outs of many different probability distributions. This includes the normal, binomial, beta, gamma, exponential, and Poisson. Surprisingly I never ran into one of the most popular distributions in popular culture: the Pareto distribution.
You may have heard of the 80/20 rule? Most commonly you hear about 80% of the wealth is controlled by 20% of people. Maybe 99% of book sales are generated by 1% of authors? These numbers don’t need to add up to 100%. We could just as easily say 70% of productivity comes from 10% of workers, or 90% of your musical abilities is generated from 30% of your practice. But no matter how you slice it there’s a sense of skewness of how some percentage of input generates a disproportionate amount of output. My goal in this post is to mathematically describe how the Pareto distribution arises from simple assumptions, and how it captures this skewness phenomenon.
Let’s describe a real life property, such as a random individual’s age, via a random variable  . Assume
. Assume  . That is follows an exponential distribution with PDF and CDF
. That is follows an exponential distribution with PDF and CDF
 and
and  for
for  .
.
From here let’s assume that everyone’s income grows over time at a constant rate of return. Ignore units and just assume everyone starts life on equal footing with a net worth of 1. Then we’ll use  to describe a random individual’s net worth, where
to describe a random individual’s net worth, where  is the rate of return. The CDF of Y is derived like so…
is the rate of return. The CDF of Y is derived like so…
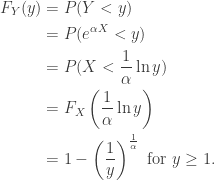
The PDF comes from taking the derivative of the CDF. We have…
 .
.
This is the Pareto distribution (typically parameterized to remove the reciprocal of ).
Consider  . This value tells us the proportion of the population that makes an income above
. This value tells us the proportion of the population that makes an income above  . A natural question to ask is how much wealth does this portion of the population control? To answer this question first let’s calculate the following quantities.
. A natural question to ask is how much wealth does this portion of the population control? To answer this question first let’s calculate the following quantities.
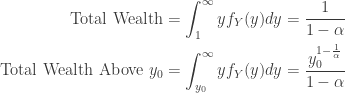
Taking the ratio of the above terms we can define a new function,  , to get the proportion of wealth owned by the top p percentile of the population.
, to get the proportion of wealth owned by the top p percentile of the population.

where the following substitution is applied
 .
.
Now let’s consider finding a value that expresses the most popular form of the Pareto Principle, i.e. the 80/20 rule. Simply setting 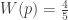 and
and  we solve and get
we solve and get  .
.
In our every day world 86% may seem like an unrealistic rate of return, but keep in mind that we never gave units for our underlying distribution of age. If the units are in decades and you assume a person lives only 10 years on average, then you achieve this same level of inequality with just a 9% annualized rate of return. Of course this model is highly simplified since human lifespans don’t follow an exponential distribution with a 10 year mean. Still, it speaks volumes to how inequality can arise from something as innocuous as age and a modest return on investment.
Oddly enough there’s nothing special about the Pareto distribution that is unique in capturing this sense of inequality. We could have used this same methodology for many distributions. A natural question then becomes how must change to capture the 80/20 rule when you assume a different underlying distribution for age besides the Exponential distribution.


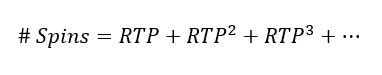
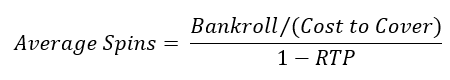
 is given by
is given by  . Furthermore, let’s say we wish to construction a function,
. Furthermore, let’s say we wish to construction a function,  , that indicates how surprising a given message is. How might you want to construct such a function? An intuitive approach might be to give a few constraints on things we want from
, that indicates how surprising a given message is. How might you want to construct such a function? An intuitive approach might be to give a few constraints on things we want from  , then
, then 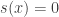 . A event that is certain should yield no surprise.
. A event that is certain should yield no surprise. , then
, then  . The surprise of an message knows no bounds.
. The surprise of an message knows no bounds. .
.![H(X) = E[s(X)] = \sum p(x) \log \frac{1}{p(x)}](https://s0.wp.com/latex.php?latex=H%28X%29+%3D+E%5Bs%28X%29%5D+%3D+%5Csum+p%28x%29+%5Clog+%5Cfrac%7B1%7D%7Bp%28x%29%7D&bg=ffffff&fg=333333&s=0&c=20201002)
 . In fact,
. In fact, 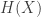 reach its maximum when all messages are equally likely.
reach its maximum when all messages are equally likely.