In 1948 Claude Shannon published a landmark paper that gave rise to a new field of science: Information theory. A few years ago I also published my not-so groundbreaking post on how we can make inferences from biased sources of information. I’m going to follow up that post by assessing the quality of a news source by using one of the key insights of Shannon’s research.
Let’s say you have a random source of information. The probability that it outputs a given message 


- If
, then
. A event that is certain should yield no surprise.
- As
, then
. The surprise of an message knows no bounds.
One such function that satisfies these conditions is

From here we can go a step further and measure the average surprise of a source (aka the Shannon Entropy) given by
![H(X) = E[s(X)] = \sum p(x) \log \frac{1}{p(x)}](https://s0.wp.com/latex.php?latex=H%28X%29+%3D+E%5Bs%28X%29%5D+%3D+%5Csum+p%28x%29+%5Clog+%5Cfrac%7B1%7D%7Bp%28x%29%7D&bg=ffffff&fg=333333&s=0&c=20201002)
If we take this formula in its most literal sense it seems to reinforce our own intuitions about the quality of a news source. If a news source is always pro or anti one side or the other then it’s Shannon entropy is 0. i.e. There is no information to be gleaned from the signal. But if it occasionally surprises us then 
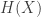
Do you buy this literal interpretation of Shannon’s equations? If not, do you think it can be adjusted somehow?
