Standard deviation is the most commonly used metric for measuring the volatility, or spread, of data. Besides mean average, it is the most commonly used metric in data science to the point where we never stop to think about why it’s used.
The formula for standard deviation is given by:

Not the simplest formula, but it does its job in capturing how data deviates from its mean. Except there is a simpler, more intuitive formula available to us. This metric is called Mean Absolute Deviation (or MAD for short). The formula looks like this:
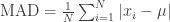
If you want to know how spread out your data is, doesn’t it make more sense to find the mean, then take the average distance of all the data from that mean? I see no reason why not.
So why is standard deviation the industry standard for measuring spread? I think it’s partly an accident of history, and partly due to the fact that square functions are easier to work with in mathematics (and lead to nicer advanced results).
Compare the square function to the absolute value function below.


Calculus has no way of dealing with that sharp corner on the right.
Okay, so we can see that there are alternatives to standard deviation. What difference does it make when analyzing data?
The consequences of using a 2nd order (or higher) polynomial when measuring spread is that data points further from the mean are weighted higher. Consider the comparison of the two data sets below:

MAD is constant between the two, but standard deviation INCREASES if we included data points that are further out.
Is this good or bad? It just depends on what you’re looking for. Are you more interested in detecting possible outliers between two data sets? Use standard deviation. More interested in how the data deviates from the mean? Give MAD a try.
