I’ve been taking classes in AI and Machine Learning and I’ve already bumped into this one on a few separate occasions. In my experience I usually see it in the context of Markov Decision Processes. Here it is:
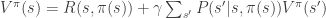
This guy is pretty nasty looking, but he’s actually not so bad once you get to know him. First let me list out what everything in there is supposed to represent…
: Think of this as value of being in a given state of the world (
) given that you tend to behave in a certain way (
).
. Think of it this way: Let’s say my state
=”go eat a sandwich.”
: Now we’re looking at the right-hand side of the equation. This is what’s called the reward function. It’s just a number in arbitrary units that tells us how good (or bad) it feels to be in state
- Note: If we stopped here the equation above would look kind of stupid, right? The value of an action at a given state is equal to the reward from taking an action at a given state? Seems kind of redundant. Luckily it has more to say!
: The discount rate where
. More on this later.
: Think of
as any state of the world after performing your action
With the meaning of these variables defined we can think of the 2nd term in the equation as an expected value. Specifically, the expected value of our future returns given our present behavior:
![V^\pi(s) = R(s,\pi(s)) + \gamma \mathbb{E}[V^\pi(S)|s,\pi]](https://s0.wp.com/latex.php?latex=+V%5E%5Cpi%28s%29+%3D+R%28s%2C%5Cpi%28s%29%29+%2B+%5Cgamma+%5Cmathbb%7BE%7D%5BV%5E%5Cpi%28S%29%7Cs%2C%5Cpi%5D+&bg=ffffff&fg=333333&s=0&c=20201002)
Even though you won’t typically see the Bellman Equation unless you take some very specialized coursework in machine learning, I couldn’t help but feel sense of familiarity with this one the first time I saw it. Then it hit me: In my economics classes! Every business student is familiar with discounted cash flow. In this case we’re not trying to calculate the net present value of an investment, we’re trying to calculate the net present value of an agent’s behavior.
The discount rate
